Self-Learning Omi Card Game Agent
~85% win rate against random decision-making bot
Built a self-play reinforcement learning agent that reached an ~85% win rate against a random-choice bot.
Project Overview
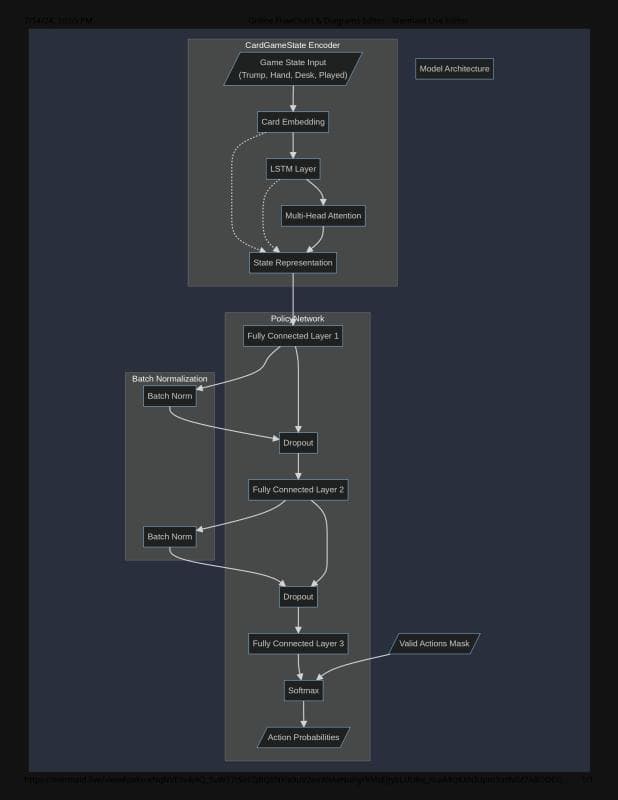
Built a reinforcement learning agent for the Sri Lankan card game Omi using a neural network CardGameState encoder and PolicyNetwork trained with the REINFORCE algorithm. The agent learned through self-play without human gameplay data and reached an ~85% win rate against a random-choice bot after 200,000 episodes.
Project Description
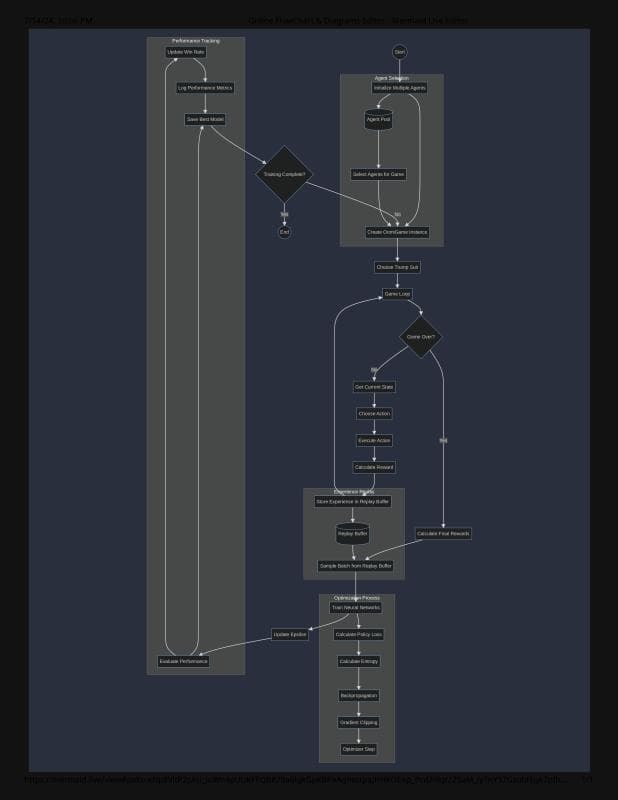
This project explores how an AI agent can learn the Sri Lankan card game Omi through self-play without using human gameplay demonstrations. The agent had to learn strategy in an imperfect-information game where not every card is visible.
- Implemented self-play training for a custom card game with incomplete information.
- Technical approach: designed a CardGameState encoder and PolicyNetwork in PyTorch, then trained with REINFORCE optimization.
- Trained with REINFORCE, experience replay, gradient clipping, and batch normalization.
- Outcome: reached an ~85% win rate against a random-choice bot after 200,000 self-play episodes on an NVIDIA Tesla P100 GPU.
Technologies Used
PythonPyTorchNumPy
Project Links
Project Gallery